

ChatGPTやCopilotなど、生成AIを試して「業務にも使えるかも」と感じた方は多いでしょう。
資料作成などの業務支援ではすぐに効果が見え始めています。
一方で、AI分析に踏み込もうとすると、こんな疑問が立ちはだかります。
- 「分類とクラスタリングって、何が違うの?」
- 「どちらをどう使えばいいのか分からない…」
実はこの違いがわかるだけで、AIを活かす道筋が見えてくるのです。
この記事では、分類とクラスタリングの基本的な違いと、
実務でどう使い分ければ業務改善に直結するのかを、具体例とともに解説します。
そもそも「分類」って何?「クラスタリング」って何?
AI分析の世界に足を踏み入れると、まず最初に出てくるのがこの2つの言葉──分類とクラスタリング。
どちらも「データをグループに分ける」手法のように見えますが、実は考え方の前提がまったく違うものです。

分類(=教師あり学習)
分類とは、あらかじめ正解ラベルがある状態で、データをそのラベルに当てはめていくことです。
例えば以下のようなイメージ:
- 「このレビューはポジティブかネガティブか」
- 「この問い合わせは返品か製品不良か」
- 「この文章はスポーツ記事か政治記事か」
つまり、「すでに決められたルールに従って、データを仕分ける」分析です。
クラスタリング(=教師なし学習)
一方、クラスタリングは正解が決まっていない状態で、「データ同士の似た傾向」をもとに自動でグループ分けを行う手法です。
- 「このグループは“価格に関するコメント”が多い」
- 「このグループは“配送の遅延に対する不満”が多い」
といったように、似た傾向をもつデータを発見し、それに意味づけしていくプロセスです。
わかりやすいたとえ話:カスタマー対応の「仕分け」と「傾向探し」
分類 → 「仕分けルールが決まっている問い合わせ振り分け」

カスタマーサポートで、問い合わせを受けたときにこういう仕分けをすることがあります:
- 返品対応 → Aチーム
- 操作方法の質問 → Bチーム
- 製品不良 → Cチーム
これは、「事前に決められたカテゴリ(ラベル)」に従って、対応を分ける作業です。
新しい問い合わせが来たときも、ルールに従って自動で「これは返品対応ですね」と仕分けされます。
クラスタリング → 「なんか似た内容の問い合わせが増えてない?」

一方で、こういう気づきもあるかもしれません:
- 「最近“電源が入らない”って問い合わせが増えてるような…?」
- 「“アプリが重い”という声が、SNSでもよく見かける…」
こういった気づきは、あらかじめラベルがあるわけではなく、似た内容を“発見する”作業です。
クラスタリングは、こうした「潜在的に増えている傾向」を自動でグループにまとめ、見える化するのに役立ちます。
実務での違いと活用シーン
「分類とクラスタリング、考え方はわかったけど、実際にどんなときに使うの?」
そんな疑問に答えるために、まずは活用シーンの違いを整理してみましょう。
実務での使いどころ比較
| 分類(ラベルあり) | クラスタリング(ラベルなし) | |
|---|---|---|
| 商品レビュー分析 | ポジティブ / ネガティブに自動分類 | 類似した意見で自然にグループ化(価格/味/対応など) |
| 問い合わせ対応 | 「返品」「製品不良」「使い方」などに自動仕分け | よくある相談内容を傾向別に抽出(未定義のカテゴリを発見) |
| クレーム管理 | 過去のクレーム種別から新しいクレームを自動分類 | 潜在的な不満傾向を発見(気づかれていないトピックを明確化) |
| 顧客分類 | 「優良顧客」「離反リスク高」などを分類してアクション | 顧客の行動・属性から自然発生的にセグメントを抽出 |
実務では「クラスタリング→分類」の流れが効果的
特に実務で多いのが、
「そもそもどう分類していいかわからない」
というケース。そんなときは、まずクラスタリングで自然な傾向を見つけるのが有効です。
実践ステップの例
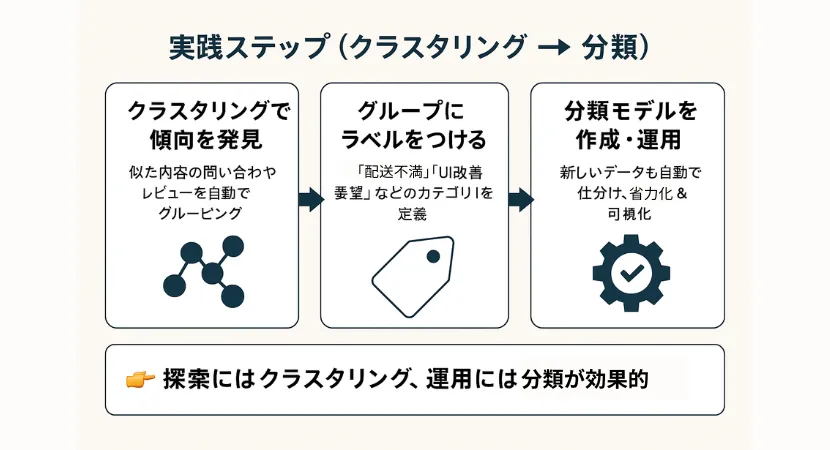
クラスタリングで探索する
→ 似た内容の問い合わせやレビューをグルーピング
→ 「配送に関する声が多い」「アプリの使い勝手に不満が集中」などが見える
発見したグループにラベルをつける
→ 「これは“配送不満”、これは“UI改善要望”」など
分類モデルを作って自動仕分けに活用
→ 次からは新しいコメントも自動で振り分けられるようにする(省力化&可視化)
このように、クラスタリングは探索フェーズで、分類は実装・運用フェーズで力を発揮します。
次のセクションでは、こうした考え方がカスタマー分析や業務改善にどう役立つかを具体例で見ていきましょう。
実務でこう使える:カスタマー分析・業務改善の例

分類とクラスタリングの違いがわかってくると、
「これ、うちの業務にも使えるかも?」と感じる場面が増えてきます。
例えば、こんな疑問を感じたことはありませんか?
- 「コールセンターの履歴、もっと簡単に整理できないかな?」
- 「お客様アンケート、たくさんあるけど結局どんな意見が多いの?」
「営業コメントの傾向を掴みたいけど、全部読むのは現実的じゃない…」
こうした声にこたえるのが、クラスタリング+分類の組み合わせです。
ケース①:コールセンター対応履歴の整理
- 大量の通話記録や対応メモをクラスタリング
- 「接客の態度」「商品の使い方」「在庫切れ」などのグループが浮かび上がる
- 分類モデルを作って、今後の問い合わせを自動で仕分け
→ 現場の対応が早くなる+集計も一瞬で可能に
ケース②:アンケート・口コミの傾向把握
- フリーテキストのアンケートをクラスタリング
- 思ってもみなかった不満や改善要望が可視化される
- 抽出された内容から、次回の設問設計やCS改善に活用
→ 現場の声を見逃さず、戦略につなげられる
ケース③:営業日報・顧客コメントの分析
- 営業が書き溜めた日報や活動記録をクラスタリング
- 顧客の関心テーマごとに分類(価格重視・競合比較・導入障壁など)
- 次の提案時に“関心別テンプレート”として再活用
→ ナレッジの属人化を防ぎ、営業活動の再現性がアップ
ポイントは「分類の“種”をクラスタリングで見つける」
実務では「ラベル付きデータ」がそもそも存在しないケースが多いため、
まずはクラスタリングで傾向を探り、そこから分類ルールをつくるのが王道です。
まとめ
AIを活用したいけれど、何から始めればいいかわからない──
そんなときはまず、「データをどう分けるか?」という視点から始めてみましょう。
分類とクラスタリングは、どちらも“分ける”手法ですが、
- 分類は「ルールがあるとき」
- クラスタリングは「ルールがまだ見えていないとき」
に使い分けるのがポイントです。
実務では、まずクラスタリングで傾向を探り、
そこから分類モデルを作って運用する、という流れが効果的。
生成AIだけでは見えづらい“データの活かし方”を学ぶことで、
AI分析の一歩目に自信が持てるはずです。

